Explaining the code of the popular text-to-image algorithm (VQGAN+CLIP in PyTorch)
This article explains VQGAN+CLIP, a specific text-to-image architecture.
You can find a general high-level introduction to VQGAN+CLIP in my previous blog post “VQGAN+CLIP — How does it work?”
Here I am looking at the specific VQGAN+CLIP implementation written by artist/programmer Katherine Crowson (aka @RiversHaveWings) which went viral in the summer of 2021.
📍 To be exact, I am looking at this Google Colab notebook. (Be aware that there might be newer versions of this notebook with more cool optimizations.)
↕️ Tip: I suggest turning on line numbering in Google Colab: Tools → Settings → Editor → Show line numbers
🤓 Extra: There is a little dictionary of Machine Learning terms at the bottom of this article: general terms and more specific terms from this implementation. Because I love dictionaries.
General facts about this notebook
- It uses PyTorch, a popular machine learning framework written in Python
- It connects two existing (open-source, pretrained) models: CLIP (OpenAI) and VQGAN (Esser et al. from Heidelberg University)
- It is structured in the following sections/cells:
— Setup, Installing libraries
— Selection of models to download
— Loading libraries and definitions
— Implementation tools
— Execution
A high-level overview of the algorithm
From my older blog post “VQGAN+CLIP: How does it work?”: “CLIP guides VQGAN towards an image that is the best match to a given text.”
Because CLIP is able to represent both text and images in the same feature space, we can easily calculate the distance between these two.
Here’s a simple visualization of the algorithm. The cycle represents one optimization iteration.
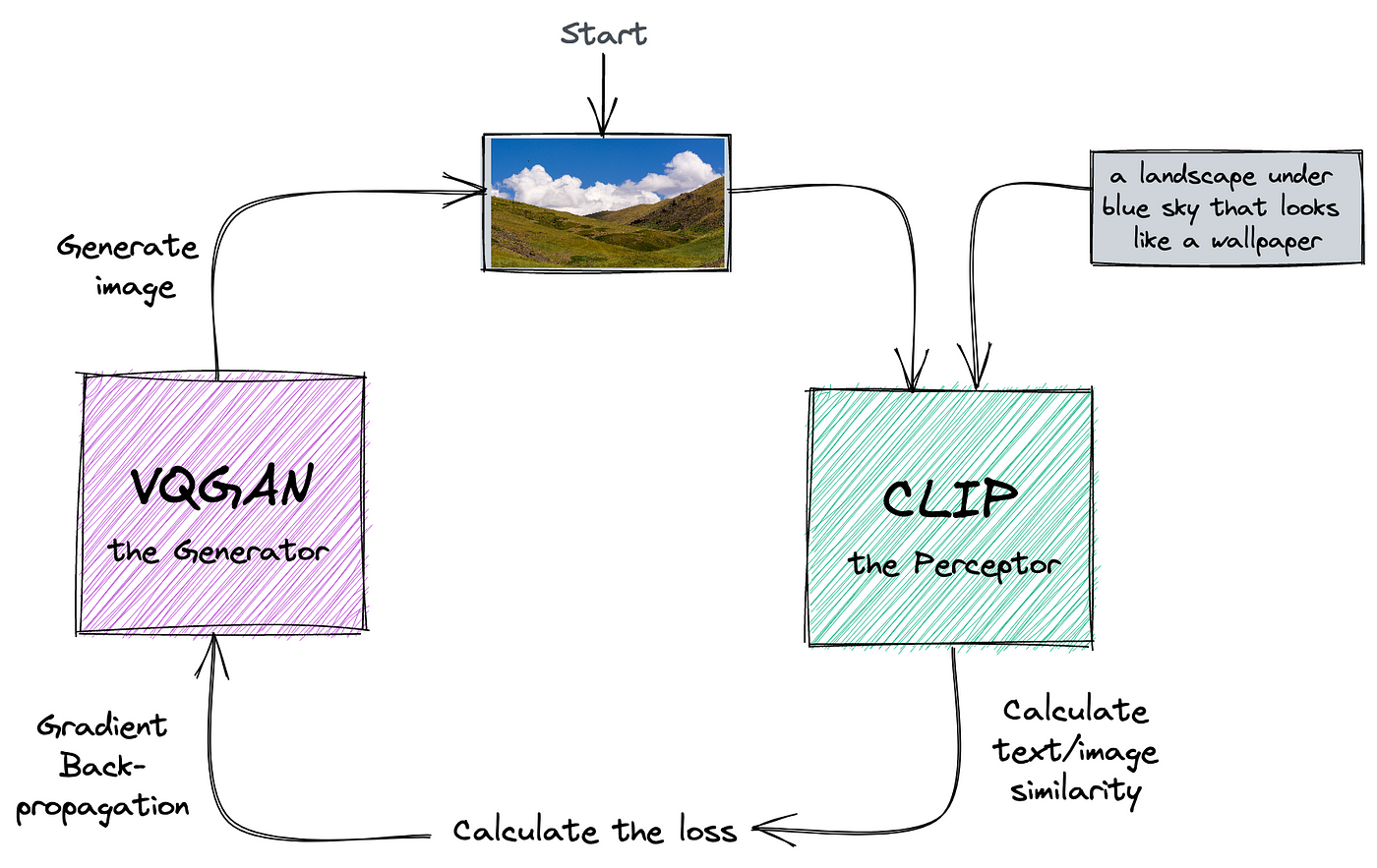
A core concept: Inference-by-optimization
In Machine Learning there is this core distinction between training and inference:
- Training is the optimization process of finding the right weights of your model in order to minimize a loss function.
- Inference is the process of using a pre-trained model to make predictions
Training is most often the resource-intensive part requiring a GPU for effective computation. Inference is, for most models, a rather light operation, it could run on a CPU and sometimes even on edge devices (such as a mobile phone or a Raspberry Pi).
The VQGAN-CLIP architecture kind of blurs the distinction of training-vs-inference, because when we “run” VQGAN-CLIP we’re kind of doing inference, but we’re also optimizing.
This special case of inference has been called “inference-by-optimization”. That’s why we need a GPU to run VQGAN-CLIP.
Variable naming choices and what they refer to
Perceptor→ CLIP modelModel(also sometimes named the “Generator”) → VQGAN modelPrompt→ the model we’re going to train when we run the notebookz→ A vector as input for VQGAN for synthesizing an imageiii→ A batch of CLIP-encoded image cutouts
The notebook step by step
STEP 0. Downloading the pre-trained models (CLIP & VQGAN)
First CLIP and VQGAN repositories are git-cloned (Cell “Setup, Instaling Libraries” lines 6 and 9).
Then we also download a pre-trained VQGAN model (Cell “Selection of models to download”): For every model there is a .yaml file containing basic model parameters and a .ckpt file that contains the weights of the pre-trained model (called a checkpoint).
The pretrained CLIP model download is a bit harder to spot: It happens in the clip.load() function (cell “Excecution”, line 16), which is documented in CLIP’s Github repository as follows: “Returns the model (…). It will download the model as necessary. The name argument can also be a path to a local checkpoint.”
STEP 1. Generating the initial z vector (Cell “Excecution”, line 29–36)
We generate an intitial VQGAN-encoded image vector. In case we’ve input a starting image this will be the VQGAN embeddings ( model.encode ) for this image. In case the user hasn’t provided a starting image it will be a tensor filled with random integers (torch.randint ), aka a random noise vector. This VQGAN-encoded image vector is referred to as z.
STEP 2. Initializing the optimizer with z (Cell “Execution”, line 39)
opt = optim.Adam([z], lr=args.step_size)The first argument in the constructor contains the parameters that you wish to optimize, in our case it’s z, aka the image vector with which we start the optimization process.
STEP 3. Instantiating the Prompt models for every text prompt (Cell “Execution”, line 46–49)
For every text prompt provided by the user:
— we encode it with CLIP
— and with this encoding, we create our own Prompt model. These models are what we’re going to train when we run the notebook
— we add this model to an array named pms (I guess this stands for “prompt models”)
STEP 4. The actual optimization Loop (Cell “Execution” line 134–144)
This simple loop does nothing more than call the train() function as many times as defined in max_iterations(as set by you the user in the cell named “Parameters”). Note: if it’s set to -1 (the default) the loop will go on forever (until you stop the cell manually or an error occurs).
The actual optimization procedure
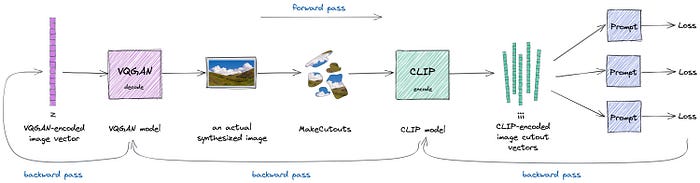
Forward pass: We start with z, a VQGAN-encoded image vector, pass it to VQGAN to synthesize/decode an actual image out of it, then we cut it into pieces, then we encode these pieces with CLIP, calculate the distance to the text prompt and get out some loss(es).
Backward pass: We backpropagate through CLIP and VQGAN all the way back to the latent vector z and then use gradient ascent to update z.
ascend_txt() Synthesizes an image with VQGAN, cut the image into pieces, encode the image pieces with CLIP, then pass them to the Prompt model(s) to calculate the loss(es), and finally saving the image to disk. (see detailed explanation of ascend_txt below)
loss.sum()
Summing the losses. Remember, loss is an array of tensors. This works in PyTorch: If you have multiple losses you can sum them up and then only call backward() once.
loss.backward()
Computing the gradients for all losses (it does not yet update the weights)
opt.step()
Calling the optimizer (which we initialized in step 2) to update z.
⛰️ What happens in ascend_txt ?
This function formulates the loss terms for optimization. It returns an array of losses per prompt.
Why is it named ascend_txt? It refers to gradient ascent, which works the same manner as gradient descent (just with a different goal: maximization instead of minimization of some function).
Here’s what’s happening in ascend_txt:
out = synth(z)We’re synthesizing an image with VQGAN ( model.decode ): based on z, the vector that is being optimized in every training step
iii = perceptor.encode_image(normalize(make_cutouts(out)))float()We create a batch of cutouts from this image and encode them with CLIP (see detailed explanation about MakeCutouts below)
for prompt in pMs:We go over each of our “Prompt” models (instances of the
result.append(prompt(iii))Prompt class) and pass the cutout-batches through it in order to calculate the loss per prompt (see detailed explanation about the Prompt model below)
imageio.imwrite(filename, np.array(img))We save the image and add metadata to it via steganography (see detailed explanation below about Steganography)
add_stegano_data(filename)
return resultWe return an array of losses (loss per prompt).
🔥 Is it CLIP? Is it VQGAN? What exactly is being trained or optimized in this notebook?
We’re not training a VQGAN model and we’re also not training a CLIP model. Both models are already pretrained and their weights are frozen during the run of the notebook.
What’s being optimised (or “trained”) is z , the latent image vector that is being passed as an input to VQGAN.
🔥 The Prompt class
A model called “Prompt” is the place where we calculate how similar image and text are (the loss). There might be more than one of these models in case that a) there was more than one prompt in the user input, or b) a destination image was defined by the user.
The class Prompt subclasses the PyTorch NN module base class. Note: When calling an instance (let’s say we named itprompt ) of the Prompt class withprompt()we are actually calling the forward() method of the Prompt class.
The forward() function of the Prompt model is the core of the algorithm, it calculates how similar image and text are.
It’s important to understand what is referred to by input , self.embed and dist here!input is the (CLIP encoded) image. Or more accurately: a batch of image cutouts.self.embed is the (CLIP encoded) text prompt that the model was instantiated with.dists stands for “distance” and refers to the mathematical distance between the embeddings of input and text.
The return value (the actual loss) of the forward function refers to this distance. It is actually a tensor representing the loss that looks like this:
tensor(1.0011, device=’cuda:0', grad_fn=<MulBackward0>)
(btw, the grad_fn property means that a previous function (MulBackward0) resulted in having the gradients calculated. History is always maintained in these PyTorch tensors, unless you specify otherwise)
✂️ MakeCutouts
CLIP can only deal with low-resolution images as input. However, VQGAN is capable of creating high-resolution images. In order to compromise between the two, we cut the image into pieces and pass them to CLIP as a batch.
On top of cutting the images into pieces MakeCutouts does a couple of image transformations: Distortions, horizontal flip, add blur, and more. It uses kornia for this, a computer vision library that provides functions for image augmentations.
Why these transformations? In his wonderful blogpost Ryan Moulton explains:
“Much like how digital artists flip their canvas to double check their proportions, and artists in traditional media will rotate around their canvas to view it from different angles as they’re working, giving CLIP randomly rotated, skewed, slightly blurred images produces much better results.”
Other interesting aspects of this notebook (Steganography, etc.)
🕵️♀️ Steganography
The notebook uses steganography to add metadata to each generated image saved on disk, such as: text prompt, the type of model, the random seed, the iteration number and more.
This is handy in case you want to keep track of your experiments, reproduce some of your own results or see how other people created the images they published on the internet.
Steganography is the practice of concealing messages in a file or a physical object that can not be noticed by the naked eye. This notebook uses the “LSB” steganography technique, which stands for “least significant bit”. The idea is to store the hidden message by overwriting the least significant bit of each pixel of the image. Here’s a quick explainer of LSB.
Want to quickly check which information is hidden in an image? You can use an online Stegano Decoder like this one.
Be aware that once you edit the image (e.g. change the filesize or do some Photoshop edits) this hidden information will be gone.
A little dictionary
Checkpoint
A capture of the models internal state (weights and other parameters) at a certain time in training. Necessary for inference or for resuming training.
Embedding
A low-dimensional, learned vector representation into which you can translate high-dimensional vectors. Generally, embeddings make ML models more efficient and easier to work with.
Loss
A measure of how different a model’s predictions are compared to the actual label of the data. Basically a measure of how bad the model is. To determine the loss, a model must define a loss function.
Loss function
A function for calculating the loss.
One-hot encoding
A technique for representing categorical data. The encoding has the shape of a matrix with binary data.
Seed
The number used to initialize the state of a (pseudo-) random number generator. If you use the same seed the generator will produce the same output. This is useful for reproducibility.
Steganography
Steganography is the practice of concealing a messages in a file or a physical object that can not be noticed by the naked eye.
Tensor
A type of data structure or mathematical object that is similar to a vector or a matrix. Mathematically, tensors are a superset of vectors. In PyTorch it’s the core data structure: all the inputs and outputs of a model, as well as the model’s parameters and learning weights, are expressed as tensors.
- Video: Mathematical explanation
- Video: Tensors in PyTorch
Vector Quantization
A technique for easing computation (which also minimizes carbon footprint). It replaces floating points with integers inside the network.
Z-Vector
A vector containing random values from a Gaussian (normal) distribution. It is usually passed as the input into a pretrained GAN generator which results in generating a real-looking fake image.
Cool Resources
- Blogpost by Ryan Moulton on how he tweaked the code of VQGAN+CLIP to generate interesting panorama images: https://moultano.wordpress.com/2021/08/23/doorways/
- An explainer on the CLIP+BigGAN implementation by Hao Hao Tan: https://wandb.ai/gudgud96/big-sleep-test/reports/Image-Generation-Based-on-Abstract-Concepts-Using-CLIP-BigGAN--Vmlldzo1MjA2MTE
- “VQGAN+CLIP how does it work” by Alexa Steinbrück https://alexasteinbruck.medium.com/vqgan-clip-how-does-it-work-210a5dca5e52
- “Alien Dreams: An Emerging Art Scene” by Charlie Snell: https://ml.berkeley.edu/blog/posts/clip-art/
- Interview (video) with Ryan Murdock (aka @advadnoun) by Derrick Schultz (Artificial Images): https://www.youtube.com/watch?v=OYWGSDeQYlc
- Twitter thread by Tanishq Mathew Abraham: https://twitter.com/iScienceLuvr/status/1468115406858514433
- “The illustrated VQGAN” by Lj Miranda, especially the Appendix with a diagram of the “family tree” of VQGAN+CLIP and how it came to be! https://ljvmiranda921.github.io/notebook/2021/08/08/clip-vqgan/
